[Contents] [Prev] [Next] [End]
The first two chapters of this guide give a quick introduction to production job scheduling and LSF JobScheduler. You should be able to begin using JobScheduler after reading these chapters. The rest of the guide contains more detailed information on JobScheduler features and commands.
Production job scheduling has been an integral part of mainframe data processing operation for decades. With the emergence of distributed computing along with Unix and Windows NT workstations and fileservers, the system architecture has changed drastically, calling for a new approach to production job scheduling.
LSF JobScheduler is a distributed production job scheduling product from Platform Computing Corporation. It is a separately licensed component of the Load Sharing Facility (LSF) Suite, a general purpose distributed computing system that unites a network of computers into a single system.
JobScheduler integrates heterogeneous servers into a 'virtual mainframe' to deliver high availability, robustness and ease-of-use. It provides the functions of traditional mainframe job scheduling with transparent operation across a network of heterogeneous UNIX and NT systems. JobScheduler offers GUI input tools in addition to the standard command line interface.
In production data processing environments, jobs often need to be processed repetitively and periodically according to user-defined calendars. Job processing may also be conditional upon certain events occurring such as the arrival of a specific file or the availability of a data set.
Calendars can be defined in JobScheduler to drive time dependent job processing. Flexible time expressions can be used to define time events that constitute a calendar. Calendars are defined independent of jobs; jobs can be associated with calendars.
Job scheduling in JobScheduler can also be driven by arbitrarily configured network-wide events. This can be used, for example, to detect a change in the size of a file or the mount of a tape to trigger production jobs.
JobScheduler is designed to continue operating even if some of the servers in the system are unavailable. A dynamic master succession algorithm ensures that as long as one server is up the jobs will continue to be scheduled on the remaining hosts. Even if the entire network goes down, no jobs will be lost because all calendars, job records and events are logged in a configured file system. When the system comes back up, it will recover the state of the JobScheduler and continue operation.
JobScheduler allows you to control a job's execution upon the completion, failure, or start of other jobs. For example, you can configure the system to start several main processing jobs only after a data preparation job has completed, then you can start the post-processing job after all the main processing jobs are done. These jobs do not have to run on the same host.
JobScheduler can also be configured to run a pre-execution command before job execution and a post-execution command after job execution. This is useful if some preparation work (for example, mounting a device) has to be performed successfully before starting the job and/or when cleaning up is needed after the job finishes.
JobScheduler maintains full history data of all jobs. The history information tells you what has happened to your job since it was submitted.
JobScheduler provides a rich set of command line and GUI tools to define, monitor and manage the workload using any desktop as the system console. Typically you define your calendars and jobs together with any interdependency using the GUI tools xbcal and xbsub. Once these are set up, JobScheduler will ensure that jobs are run according to the conditions and policies specified.
You can keep close track of your jobs with JobScheduler using the GUI program xlsbatch. As well as monitoring the status of jobs, the system allows you to perform various operations on them, including:
With JobScheduler, you can target jobs to specific servers or you can allow the system to match resource requirements of your jobs to the capabilities of the servers. JobScheduler dynamically collects system load information about all aspects of computing resource including CPU, memory, I/O, disk space, interactive activities, etc. Jobs are dynamically scheduled to run on the best server available. For example, you can submit a job indicating it requires 100 megabytes of temporary storage space before it starts. JobScheduler will ensure that the server the job is run on satisfies the condition.
JobScheduler comes with a comprehensive set of tools for monitoring your cluster. These tools allow you to view your cluster of resources from any node of the cluster so that you know the dynamic resource usage of all your machines.
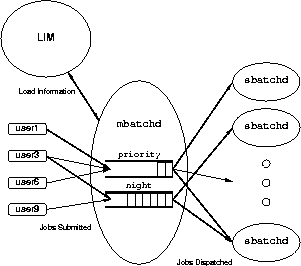
Production job scheduling and load sharing in JobScheduler is based on clusters. A cluster is a named group of machines configured to share resources transparently. It consists of one or more server hosts and zero or more client-only hosts. A server host is a machine that runs JobScheduler daemons and executes user jobs. A client-only host does not run JobScheduler daemons and does not execute user submitted jobs, but users on a client-only host can still use the JobScheduler user interface such as commands and GUIs.
One of the server hosts is configured as the master for the cluster. It runs the master scheduler daemon, mbatchd. All server hosts run the slave execution server, sbatchd, which manages jobs dispatched by the master scheduler. Each server host also runs a Load Information Manager daemon, lim. It monitors the availability of resources and makes this information available to JobScheduler and other LSF utilities.
Each cluster has one or more cluster administrators. A cluster administrator is a user account that has permission to change the JobScheduler configuration and perform other maintenance functions. The cluster administrator decides how the JobScheduler cluster is configured.
The master scheduler maintains the status of all entities defined in the system including jobs, events, calendars, and queues.
A job is a program or command that is scheduled to run in a specific environment. A job has many attributes specifying the scheduling and execution requirements. Job attributes are specified by the user who submits the job. JobScheduler uses job attributes, system resource information and configured scheduling policies to decide when, where, and how to run the job. Each job is assigned a unique job identification number by the system. You can associate your own job names to make referencing easier.
An event is a change or occurrence in the system such as the arrival (creation) of a specific file, a tape becoming on-line, a prior job completing successfully, or a particular time, that can be used to trigger jobs. JobScheduler responds to four types of events:
When defining a job, it is possible to specify any combination of events that must be satisfied before the job is considered eligible for execution.
A calendar consists of a sequence of time events, during which a job can be scheduled. Calendars are defined and manipulated independently of jobs so that multiple jobs can share the same calendar. Each user can maintain a private set of calendars, reference calendars of other users, or use the calendars configured into the system. A calendar can be modified after it has been created. Any new jobs associated with it will automatically run according to the new definition.
Production job scheduling provides efficient, timely execution of mission-critical jobs. When you submit a job, it is placed into a queue. The JobScheduler system runs jobs from the queue based on the scheduled time and when the appropriate resources are available. Jobs from a queue can be dispatched to any server hosts in your cluster that are configured to run jobs for the queue.
A queue can be configured with many features that make your life easier. JobScheduler allows you to define various types of services by configuring different queues. For each queue, you can configure a rich set of parameters that customize job scheduling policies, job execution behavior, and resource allocation constraints.
Copyright © 1994-1997 Platform Computing Corporation.
All rights reserved.