[Contents] [Prev] [Next] [End]
A job is an operation that a user asks JobScheduler to automatically perform within the cluster when certain conditions are met. The operation can be the execution of a shell script, or a command line.
A job can be a one-time job, which is run only once and then leaves the system forever, or a repetitive job, which is run whenever the conditions are met. Jobs can have many attributes that determine their behaviour and requirements.
After a job is submitted, it is placed into a job queue waiting for scheduling by JobScheduler. The job will be automatically started by JobScheduler on a suitable machine in the cluster once the specified conditions are met. After the job has finished, the output from the job is delivered to the user either into a specified file, or via e-mail.
Many jobs are repetitive jobs. A repetitive job is featured by its dependency on a calendar. If the job is a repetitive job, then the job is again put into the queue waiting for the next schedule after it finishes one run.
This chapter defines some concepts about jobs and their attributes, and describes the steps involved in submitting jobs with different attributes.
Every job in the JobScheduler is automatically assigned a jobID that uniquely identifies the job. A jobID is a positive integer that is returned by the JobScheduler when submitting a job.
You can also assign a jobName to your job for easy reference. It is used to identify a job for manipulation purposes, such as job dependencies and job grouping. This name does not have to be unique. Completely different jobs can be assigned the same name. If you do not supply a name, the system uses the name of the submitted command as the jobName.
Dependency condition is a job attribute you can specify so that your job gets started when certain events happen. Your job starts to run only if its dependency condition is TRUE.
The dependency condition is specified by a logical expression of event status as described in 'Events'. The minimum expression is jobID or jobName, which is equivalent to done(jobID|jobName) (see 'Inter-job Dependencies'). An expression can consist of one or more of the reserved keywords, identifiers, and logic operators.
You can select from seven reserved keywords: calendar, started, done, exit, ended, file, and event.
To create a more flexible dependency condition, you can use the logical operators '&&' (AND), '||' (OR), '!' (NOT) and parentheses '()'.
You can also specify resource requirements for your job. Resource requirements specify the required resources before the job can be scheduled to run on a host. This is useful especially when your cluster consists of machines with different architectures, operating systems, or hardware/software resources.
By specifying resource requirements, your job is guaranteed to run on a host with the desirable resources. For example, if your job must run on a host with the Solaris operating system, you can specify such a requirement so that JobScheduler will make sure that only Solaris machines are considered as candidate hosts for the job.
For more details about resource requirements, see 'Resource Requirements'.
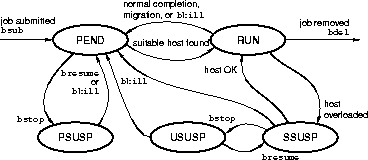
After a job is submitted to JobScheduler, it goes through a series of state transitions until it completes. The possible states of a job during its life cycle are shown in Figure 22.
Most JobScheduler jobs progress through only two states:
A job remains pending until all conditions for its execution are met. The conditions include dependency conditions, resource requirements, and JobScheduler policies. The dependency conditions and resource requirements are defined when you submit the job. The scheduling policies are configured by your cluster administrator.
The run of a job may terminate abnormally for various reasons. Termination may happen from any state. An abnormally terminated job returns to PEND status and is rescheduled. A job may terminate abnormally for a number of reasons.
Repetitive jobs go back to PEND status after they finish, waiting to be scheduled for future runs. A repetitive job continues to go through the states of RUN and PEND until it is removed from the system with the bdel command.
Jobs may also be suspended at any time. A job can be suspended by its owner, by the cluster administrator, or by the JobScheduler. There are three different states for suspended jobs: PSUSP, USUSP, and SSUSP. The queue policy is the most important factor determining whether the system will suspend your job.
You use the bsub command to submit a job to the system. The bsub command is a very complex program with many optional arguments. Some of the more important ones allow you to specify the input and output files used by your job, the hosts the job will run on, and the queue the job will run from.
Each job has a name, a job ID, and a command to execute.
bsub [options] [-J job_name] [command [argument ...]]
The job_name is a string of text declared with the -J option. If the string contains blanks or special characters, it should be placed within quotes as well. When you submit the job to the system, a jobID is assigned and displayed. If you do not supply a name, the system uses a portion of the command name as the default job name.
% bsub -J JobSubmit find ~ -name core -atime +7 -exec rm {} \;
Job <7491> is submitted to default queue <default>.
Since this job is not associated with a calendar condition, it is a simple one-time job. To define a repetitive job, associate it with a calendar, or make it depend on another repetitive job.
You can also submit your job using the GUI application xbsub as shown in Figure 23.
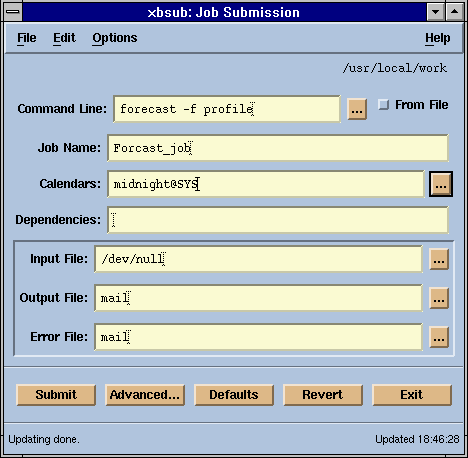
When more than one queue is available, you need to decide which queue to use. If you submit a job without specifying a queue name, JobScheduler chooses a suitable queue as the default queue.
Use the bparams command to display the default queue:
% bparams Default Queues: normal Job Dispatch Interval: 20 seconds Job Checking Interval: 80 seconds Job Accepting Interval: 20 seconds
This command displays JobScheduler parameters configured by your cluster administrator
You can override the default by defining the environment variable LSB_DEFAULTQUEUE.
% setenv LSB_DEFAULTQUEUE priority
The default queue is normally suitable to run most jobs for the user. If you want to submit jobs to queues other than the default queue, you should choose the most suitable queue for each job.
It is important that you choose the correct queue for your job. The factors affecting your decision are user access restrictions, size of the job, resource limits of the queue, scheduling priority of the queue, active time windows of the queue, hosts used by the queue, the scheduling load conditions, and the queue description. Use the bqueues command with the -l option to get this information.
The -u user_name option specifies a user or user group so that the bqueues command displays only the queues that accept jobs from these users.
The -m host_name option allows you to specify a host name or host group name so that the bqueues command displays only the queues that use these hosts to run jobs.
You must also be sure that the queue is enabled. See 'Viewing the JobScheduler Queues' for more information about bqueues command.
The following examples are based on the queues defined in the default configuration. Your JobScheduler administrators may have configured different queues.
% bsub -q night -J NightWork command
% bsub -q priority -J ImportantJob command
% bsub -q short -J QuickJob command
If you want to restrict the set of candidate hosts for running your production job, use the -m option to the bsub command.
% bsub -q idle -m "hostA hostD hostC" -J hostSelect command
This command submits your job to the idle queue and tells JobScheduler to choose one host from hostA, hostD, and hostC to run the job. All other scheduling conditions still apply---the selected host must be eligible to run the job.
You can also specify your preference of hosts:
% bsub -q night -m "hostA hostB+1 hostC+2" -J prefHostJob command
This tells JobScheduler that the job should be run hostC if it satisfies the requirements, otherwise run it on hostB. hostA should be used only if neither hostC or hostB can run the job.
When one of your jobs completes or exits, the system by default sends you a job report together with the job's standard output (stdout) and error output (stderr) by electronic mail. The output from stdout and stderr are merged together in the order they were printed, as if the job was run interactively.
If you want mail sent to another e-mail address, specify the -u username option to the bsub command. Mail associated with the job will be sent to the named user instead of to you.
% bsub -u user4 -J OtherUser command
If you do not want output to be sent by mail, you can specify stdout and stderr files. You can also specify the standard input file if the job needs to read input from stdin.
% bsub -q night -i job_in -o job_out -e job_err -J FileJob command
In the example, you submit your job to the night queue. The job reads its input from file job_in. Standard output is stored in file job_out, and standard error is stored in file job_err. If you specify the -o outfile argument and do not specify the -e errfile argument, the standard output and error are merged and stored in outfile.
The output file created by the -o option normally contains job report information as well as the job output. This information includes the submitting user and host, the execution host, the CPU time used by the job, and the exit status. If you want to separate the job report information from the job output, use the -N option to specify that the job report information should be sent by email.
% bsub -N -o job_out -e job_err -J EmailReport command
The output files specified by the -o and -e options are created on the execution host.
Many jobs in a production environment are operations in response to various events. Thus the scheduling of such jobs are dependent on specific events happening.
Use the bsub command with the -w option to submit a job with dependencies to the system.
bsub [-w depend_cond] [command [argument ...]]
The dependency condition is specified with the -w option followed by one of the reserved keywords, an identifier, and logic operators. To prevent the shell from interpreting parentheses or any blank or special characters, the keyword, identifier, and any logical operators should be placed within quotes.
You submit a calendar-driven job using the bsub command. The -w option is used with the calendar keyword to specify a calendar dependent job.
% bsub -w "calendar(calName)" -J jobName <command>
To view the calendars on the system, use the bcal command.
% bcal CALENDAR_NAME OWNER STATUS DURATION NEXT_EVENT_TIME Daily SYS inactive - Wed Dec 25 06:00:00 1996 Holiday SYS active 56 Wed Jan 01 00:00:00 1997 Midnight SYS inactive - Wed Dec 25 00:00:00 1996 daily user1 inactive - Wed Dec 25 08:00:00 1996 hourly user1 active 9 Tue Dec 24 16:00:00 1996 complex user1 inactive - Wed Dec 28 17:00:00 1996
Select a calendar and submit your job.
% bsub -w "calendar(hourly)" -J diskcheck find ~ -name core -atime +7 \;
-exec rm {} \;
Job <7848> is submitted to default queue <default>.
If none of the calendars available meet your needs, you can always create another calendar. See 'Creating Calendars'. Alternatively, you can use an anonymous calendar. See 'Using an Anonymous Calendar'.
System calendars are read-only calendars created by the JobScheduler administrators. They can be viewed by everybody. The system calendars can be used as normal calendars. You can use one of the system calendars to control your job by giving its name.
% bsub -w "calendar(Daily)" -J punch-clock set-clock
See 'System Calendars' for details about system calendars.
If you want to use another user's calendar, use the -u all option of the bcal command to view all of the calendars on the system.
% bcal -u all CALENDAR_NAME OWNER STATUS DURATION NEXT_EVENT_TIME Daily SYS inactive - Wed Dec 25 06:00:00 1996 Holiday SYS active 44 Wed Jan 01 00:00:00 1997 Midnight SYS inactive - Wed Dec 25 00:00:00 1996 Holiday SYS inactive - Wed Dec 25 00:00:00 1996 monthly userA inactive - Wed Jan 01 00:00:00 1997 nextWeek userA inactive - Tue Dec 31 00:00:00 1996 backup_time userB active 20 Tue Dec 24 17:45:00 1996 daily user1 inactive - Wed Dec 25 08:00:00 1996 hourly user1 active 7 Tue Dec 24 16:00:00 1996 complex user1 inactive - Wed Dec 25 17:00:00 1996
To use the other user's calendar, you must use the syntax calName@userName.
% bsub -w "calendar(monthly@userA)" -J month-start reset-payroll Job <9214> is submitted to default queue <default>.
CAUTION!
You should be aware that users may remove their calendars at any time. If your job depends on another user's calendar, it will not be scheduled if that user subsequently removes the calendar.
A special feature of the calendar dependency of the bsub command is the ability to create an anonymous calendar. Instead of placing a calendar name in the command, you type in a time expression (see 'Time Expression' ). To prevent the shell from interpreting special characters, the time expression should be placed within quotes.
% bsub -w "calendar(*:*:*:23:30)" cheque_run
An anonymous calendar is local to the job. It is created when the job is submitted and is removed when the job is removed from the system. It cannot be used by other jobs.
Some of your jobs depend on the results of other jobs. For example, a series of jobs could process time sheet data, calculate earnings and taxes, update the payroll and tax ledgers, and finally print the cheque run. Most steps can only be performed after the previous step completes.
The prior jobs are identified by the jobID number or a job name. The jobID is assigned and displayed by the bsub command when the job is submitted. The job name is a string specified by the -J jobName option. If you did not supply a name, the system uses the last 60 characters of the submitted command as the job name.
While jobID may be used to specify the jobs of any user, the job name can only be used to specify your own jobs. If you submitted more than one job with the same job name, the last submitted job is assumed.
A wildcard character '*' can be specified at the end of a job name to indicate all jobs matching the name. For example, jobA* will match jobA, jobA1, jobA_test, jobA.log, etc. There must be at least one match. If more than one job matches, it means your job depends on every one of the jobs.
There are four prior job dependency conditions: started, done, exit, and ended. See 'Prior Job Events' for the definition of these events.
Specifying only jobID or jobName is equivalent to done(jobID|jobName).
A numeric job name should be doubly quoted, for example -w "'210'", since most UNIX shells treat -w "210" the same as -w 210.
If any one of the conditional jobs is not found, the bsub command fails and the job is not submitted.
If your job only requires that the prior job has started processing (and it does not matter if it has completed), use the started keyword.
% bsub -w "started(first_job)" -J second_job time_card
If your job requires that the prior job finished successfully, use the keyword done.
% bsub -w "done(pre_process)" -J main_process cheque_run
If your job depends on the prior job failing (for example, it is responsible for error recovery should the prior job terminate abnormally), use the keyword exit.
% bsub -w "exit(main_process)" -J error_recovery re_run
When your job only requires that the prior job has finished, regardless of the success or failure (for example, the prior task may end successfully, but with a non-zero exit code), use the keyword ended.
% bsub -w "ended(cheque_run)" -J clean_up clean
Note
If you submit a job that depends on a repetitive prior job, then the newly submitted job also becomes a repetitive job, that is, it will go to the PEND status after it completes a run instead of being removed from the system.
The most simple inter-job dependency condition is a jobID or a job name.
% bsub -w 8195 jobB
Your job may depend on a number of previous jobs. In the example following, the submitted job, dependent, will not start until job 312 has completed successfully, and either the job named Job2 has started or the job named Job3 has terminated abnormally.
& bsub -w "done(312) && (started(Job2) || exit(Job3))" -J dependent command
The following submitted job will not start until either job 1532 has completed, the job named jobName2 has completed, or all jobs with names beginning with jobName3 have finished.
% bsub -w "1532 || jobName2 || ended(jobName3*)" -J NumberDepend command
You can also use a combination of calendar dependency conditions and prior job dependency conditions:
% bsub -w "done(1234) || calendar(weekly)" backup_job
Some jobs require resources that JobScheduler does not directly support. For example, a job may need to reserve a tape drive or check for the availability of a software license.
Along with the dependency conditions associated with prior jobs, bsub can also run pre-execution commands. You use the -E option to specify an arbitrary command to run before starting the main job. The pre-execution command is executed on the same host as the main job. If the pre-execution command runs successfully, the main job is started.
The standard input, output and error files for the pre-execution command are opened to the same files as the job. Standard input and output from the pre-execution command cannot be redirected.
The pre-execution command is run under the same user ID, environment, and home and working directories as the main job. If the pre-execution command is not in your normal execution path, the full path name of the command must be specified.
The pre-execution command returns information to JobScheduler using its exit status. If the pre-execution command exits with non-zero status, the main job is not dispatched. The job goes back to the PEND state and is rescheduled later.
The following example shows a job that requires a tape drive. The program tapecheck is a site specific program that exits with status zero if the specified tape drive is ready, and status one otherwise:
% bsub -E "/usr/local/bin/tapecheck /dev/rmt0l" -w "calendar(night)" runTape
The JobScheduler system assumes the pre-execution command can be run many times without having side effects. Therefore, you should be careful not to reserve the same resource (for example, if the pre-execution command reserves a software license) more than once for the same job.
Note
An alternative to using the -E option is for the JobScheduler administrator to set up a queue level pre-execution command. See 'Queue-Level Pre-/Post-Execution Commands' in the LSF Administrator's Guide for more information. Another alternative is defining site specific events and using the External Event Daemon to validate your job (see 'User Event Dependencies').
You may want a job to run after some file event has occurred. File events are submitted to the system using the file keyword.
There are four file status functions defined: age, arrival, exist, and size. The definitions of these functions are described in 'File Events'.
The age() function is typically used together with relational operators to form a logical expression which evaluates to either TRUE or FALSE:
% bsub -w "file(age(/u/db/datafile) > 4H)" command
This creates a job that runs when file /u/db/datafile is more than four hours old. Note that H here means hour. Other characters that you can use to represent a time duration include D (day) and W (week). The default is minute.
If you intend to trigger the job execution by the creation of a file, use the arrival() function. This function detects the transition of the specified file from non-existence to existence.
% bsub -w "file(arrival(/usr/data/newfile))" -R "type==hppa" command
This creates a job that runs when file newfile is detected in /usr/data directory. Also note that a resource requirement is specified so that this command should only be run on an hppa host.
Unlike the age() function, the arrival() function does not need a relational operator because the function evaluates to either TRUE or FALSE.
If you are only interested in the existence of the file instead of the transition of the creation, you can use the exist() function.
% bsub -w "file(!exist(/usr/data/lock_file))" command
Use the function size() if you want to run a job when the size of the file becomes a certain value.
% bsub -w "file(size(/var/adm/logs/log_file) >= 3.5 M)" command
The character M refers to megabytes. You could also use K to refer to kilobytes. The default is bytes. Like the age() function, the size() function also requires a relational operator to form a logical expression that evaluates to either TRUE or FALSE.
The file event you are depending on may be on another host.
% bsub -w "file(exist(hostD:/usr/local/fileA))" command
You can submit a combination of functions. The evaluation of the statement depends on the operators you use. In the following statement, the command will be run if either fileA exists or fileB arrives (is created).
% bsub -w "file(exist(/usr/data/fileA) || arrival(/usr/data/fileB))" command
The following statement will evaluate to TRUE only if fileA exists and fileB has arrived.
% bsub -w "file(exist(/usr/data/fileA) && arrival(/usr/data/fileB))" command
The following command will be run if fileA exists and its size is greater than or equal to 1MB.
% bsub -w "file(exist(/usr/data/fileA) && size(/usr/data/fileA) >= 1M)" command
Note
You must specify absolute path name of the file in a file status function.
User events are created to the system when submitting a job using the event keyword. For example, you want to define a user event to detect the status of a tape device before a backup job starts. If the status of the tape device is READY, the event becomes TRUE, otherwise it is always FALSE. You can submit the following command:
% bsub -w "event(tape_ready)" BackUp
A user event, tape_ready, is created by the system. The string "tape_ready" is then passed to the External Event Daemon (eeventd). The eeventd must be able to associate the event string passed to it with the actual device or event you are dependent on.
Note
The External Event Daemon (eeventd) is a site-specific daemon that is customized and installed by the JobScheduler administrators. See 'External Event Management' in the LSF Administrator's Guide.
File events and user events are handled by the External Event Daemon (eeventd). You can use the bevents command to check the status of external events:
% bevents EVENT OWNER STATUS SOURCE ATTRIBUTE LAST_UPDATE age(/tmp/core)>1H user1 inactive file - Dec 21 12:36:04 1996 exist(/var/adm/log) user1 active file - Dec 21 12:38:34 1996 tape_ready user1 inactive user Tape122 Dec 21 12:39:26 1996 arrival(myfile) user1 invalid file syntax e Dec 21 12:39:26 1996
The status of events are updated by eeventd. If the event specified by the user contains anything that the eeventd cannot understand, the event will be marked as invalid. An invalid event always evaluates to FALSE. In the above example, the last event is invalid because an absolute pathname is not specified for a file event.
You can submit a combination of conditions. The evaluation of the statement depends on the operators you use.
% bsub -w "done(jobA) && file(exist(fileA)) || calendar(calA)" -J jobB command
The above statement will evaluate to TRUE if jobA has completed successfully and fileA exists or if calA is active.
You can synchronize jobs by running the first job from a calendar and submitting the second job to be dependent on the successful completion of the first.
% bsub -w "calendar(daily)" -J jobA command Job <8085> is submitted to default queue <default>.
% bsub -w "done(jobA)" -J jobB command Job <8086> is submitted to default queue <default>.
In the above example, jobB will be run every time jobA completes successfully. Since jobA is a repetitive job, jobB also becomes repetitive because of the dependency. If jobA is modified to follow a different calendar, jobB will still run after jobA.
You can associate a set of jobs as a group, and treat them as a single job. Assign a job_name to one or more jobs at submission time, and later use the job_name to refer to the jobs as a group.
% bsub -w "calendar(daily)" -J job_group jobA Job <8315> is submitted to default queue <default>.
% bsub -w "file(size(fileA) >= 2M)" -J job_group jobB Job <8316> is submitted to default queue <default>.
% bsub -w "done(pre_process)" -J job_group jobC Job <8318> is submitted to default queue <default>.
See 'Managing Related Jobs' to learn how to refer to your jobs as a group.
Copyright © 1994-1997 Platform Computing Corporation.
All rights reserved.